


How to Extract Information from a PDF File
PDF (Portable Document Format) files are a popular format for sharing and distributing electronic documents. It’s no surprise that they are widely used to share books, articles, and scientific journals online due to their consistent formatting and readability.
One of the most useful features of PDFs is that they are generally read-only and designed to preserve the original appearance of the document across all devices and software. This ensures uniformity, making them ideal for sharing content with others.
However, it can be challenging to extract data from PDF files. PDFs are not designed for easy editing, so extracting text, images, or data can be difficult—especially if the file consists of scanned images instead of selectable text. In that case, you may need an editor that handles image-based PDF files.
Thankfully, there are tools available to extract information from PDF files. Some software can convert a PDF into an editable format, and OCR (Optical Character Recognition) programs can turn scanned images into selectable text.
When Might You Need to Extract Data from a PDF?
- Convert to another format: Converting PDFs to Word or Excel to make editing or reuse easier.
- Extract structured data: Pull information for use in databases or other systems.
- Reuse images: Save diagrams or graphics for presentations or reports.
- Document archiving: Store or index text for document management systems.
- Form data extraction: Retrieve filled-in data from interactive PDF forms.
Why Is PDF Data Extraction Often Difficult?
- Text as images: Many PDFs contain text rendered as images, requiring OCR to extract.
- Protected content: Some PDFs are password-protected or have restrictions on copying.
- PDFs aren’t meant for editing: Their design is for consistent viewing, not data manipulation.
- Complex formatting: Multiple columns or overlapping graphics can complicate extraction.
How to Extract Information from PDFs Using PDFelement
PDFelement is a PDF editor developed by Wondershare that offers multiple tools for editing, converting, and extracting content. It supports text, images, form fields, attachments, and full-page extraction. You can even convert PDF files into formats like Word, Excel, PowerPoint, HTML, and more.
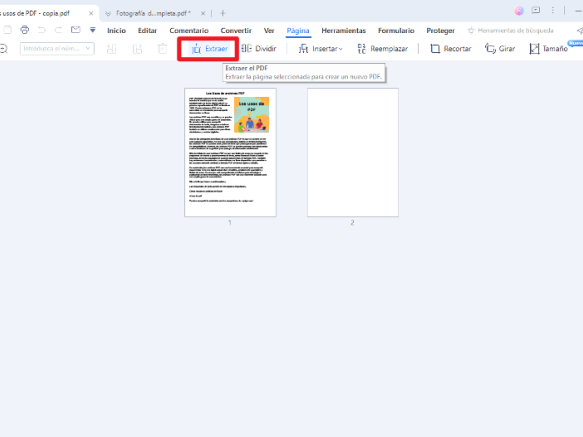
1. Extract Pages from a PDF
- Open the PDF in PDFelement.
- Click “Page” on the top toolbar.
- Select “Extract” > “Extract Pages.”
- Choose the pages you want to extract and confirm.
- Save the new PDF containing the selected pages.
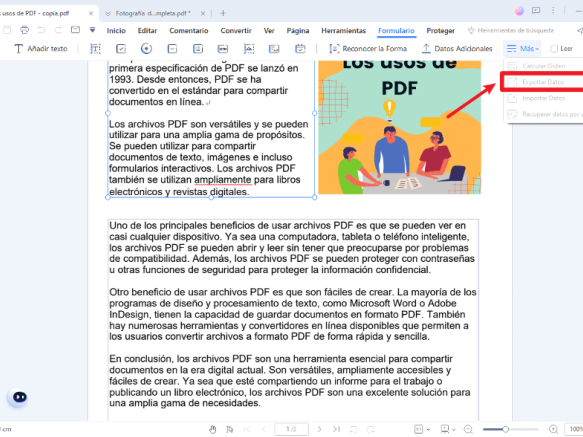
2. Extract Form Data
- Open the PDF in PDFelement.
- Click “Forms” on the top toolbar.
- Choose “Extract Data” > “Select Fields.”
- Select the fields to extract and click OK.
- Save the extracted data as a CSV or XML file.
3. Extract Text from a PDF
- Open the PDF in PDFelement.
- Click “To Text” on the top menu.
- Select “Convert” > “Convert to Text.”
- Choose the pages and click OK.
- Save the text in a .txt file.
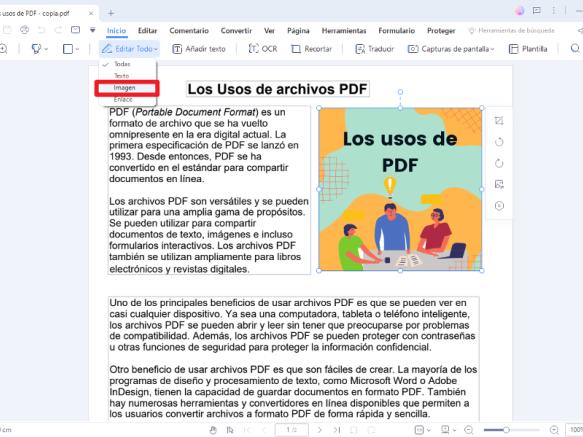
4. Extract Images from a PDF
- Open the PDF in PDFelement.
- Click “Home” on the toolbar.
- Select “Edit All” > “Image.”
- Choose the pages and click “Save Image As.”
- Save the images as PNG, JPEG, or another format.
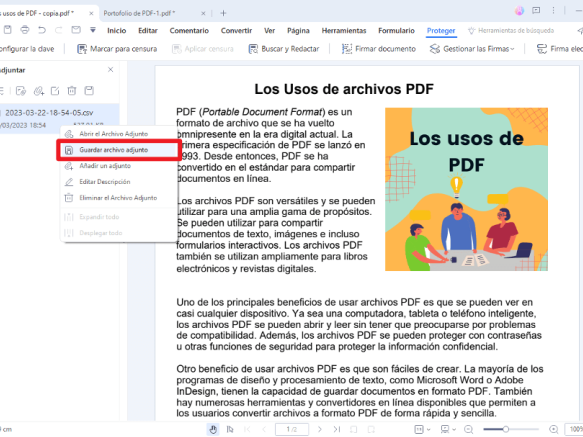
5. Extract Embedded Attachments from PDF Portfolios
- Open the PDF in PDFelement.
- Click “Attachments” on the left sidebar.
- Select the attachment and click “Save Attachment.”
- Choose where to save the extracted files.
These methods can help you get the most out of your PDFs. PDFelement is user-friendly and powerful, offering features like watermarking, digital signatures, commenting, and password protection—making it a complete PDF management tool.













 and What Is It Used For?")
